
tg-me.com/knowledge_accumulator/87
Last Update:
Eliminating Meta Optimization Through Self-Referential Meta Learning [2022] - подражаем жизни в оптимизации
Мы все слышали о ДНК и генетических алгоритмах, но суровая правда в том, что жизнь сложнее. Процесс оптимизации ДНК в ходе эволюции сам по себе закодирован в нём самом, и это не просто рандомные зашумления кода. Например, какие-то части ДНК более подвержены мутированию, чем другие. Нюансов море.
То есть жизнь - это не ДНК-параметризация + алгоритм оптимизации. Это единая сущность, оптимизирующая свою выживаемость и копирование в окружающей среде. Всё остальное - это только ограничения мира, которые кислота не выбирает. Позаимствовать эту идеологию и отказаться даже от ручного алгоритма мета-оптимизации предлагают авторы данной работы.
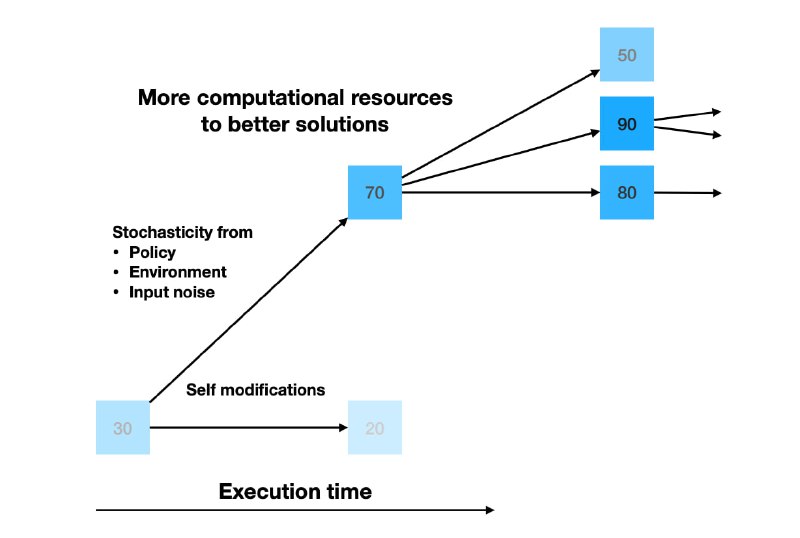
1) Выбираем архитектуру из самомодифицирующихся матриц весов из прошлого поста. Это может быть цепочка из 3 таких, т.е. 3-х слойная нейросеть.
2) Выбираем какую-нибудь задачу для этой сети. Это может быть в принципе что угодно, допустим, RL-задача. Задаём objective модели, например, суммарная награда в задаче.
3) Поддерживаем least-recently-used пул из N экземпляров весов. Изначально там один рандомный вектор.
4) Просто сэмплируем набор весов из пула с вероятностью, пропорциональной набранной им награде. Этим набором играем в среде N шагов, и модифицированную копию кладём обратно в пул, записывая собранную награду.
Эта абсолютно безумная схема как-то работает! Но на весьма простых задачах. Её в теории можно использовать для мета-мета-обучения, мета-мета-мета-обучения, и не упираться ни в какие человеческие алгоритмы оптимизации. Отвечаю на вопрос самых внимательных - в алгоритме нет рандома, и расхождение весов в разные стороны происходит засчёт рандома задачи.
Однако, мир ещё не готов и не нуждается в таких технологиях, потому что их время придёт тогда, когда потенциал обычных мета-алгоритмов будет исчерпан. Тем не менее, в идее подражать жизни и самой её сути есть что-то очень притягательное...
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/87